 Published by Matt Conran
Published by Matt Conran
Last updated on July 15, 2026
•
8 minute read
Understanding CDN architecture is crucial for IT professionals managing distributed networks and content delivery network systems. Modern CDN architectures rely on sophisticated monitoring solutions to ensure optimal performance, reduced latency, and enhanced user experience across all Points of Presence (PoPs) in geographical locations. This comprehensive guide explores CDN architecture fundamentals, website performance optimization, and how PRTG sensors maintain peak performance for end users.
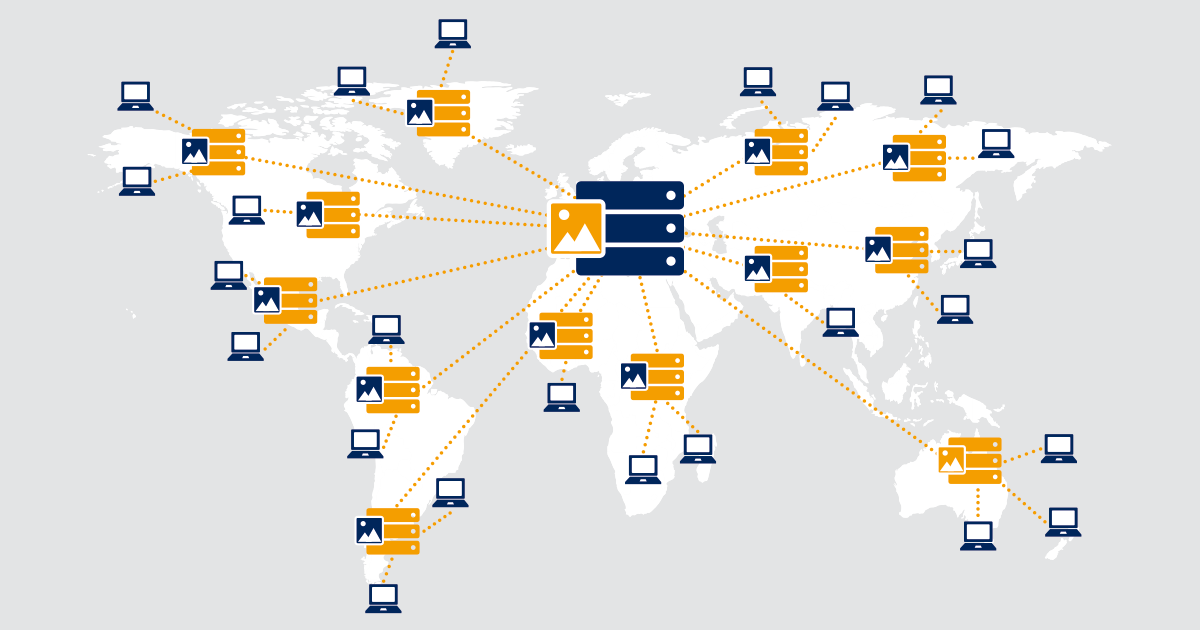
CDN Architecture Fundamentals: How PoPs Work
CDNs operate a distributed network design with edge servers, strategically placing PoP infrastructures as close as possible to end users in various geographical locations. The core of CDN architecture relies on PoPs that are small data centers containing servers and network equipment, forming a network of servers for optimal content distribution.
For example, if you have customers in Germany, you would install local PoPs there rather than having user requests travel across physical distance to different continents. This brings several benefits to user experience and website performance.
PoPs store and cache static content like HTML, CSS, and other web content. Static content is easily cacheable while dynamic content requires more complex functionality. Instead of user requests travelling to an origin server in a far location, they can request cached content from the local CDN server, reducing physical distance. This decreases latency and RTTs (Round Trip Times), resulting in better web application performance and faster page load times.
If the local PoP lacks requested content, it retrieves it from the origin server, optimizing bandwidth utilization and connectivity through existing TCP connections.

Optimized CDN Architecture Design
Most CDN providers aim to operate in a clean stateless design, offering better operations, cleaner networking topology, and improved CDN functionality. Stateless devices improve scalability and performance compared to devices that hold state, which require more processing power and impact CDN performance.
Many CDN PoP architectures run equal-cost multi-path routing (ECMP) right down to the web server hosts. ECMP enables packet processing across multiple paths, improving redundancy and high availability while handling traffic spikes. Within a CDN solution, ECMP removes the need for heavy load balancers, reducing bandwidth costs through cheaper Layer 3 switches and BGP routing protocols.
Load balancing is now based on pure IP addresses, which can be done in hardware without specialist devices, reducing downtime and improving CDN server response times.
Monitoring CDN Architecture Performance
Effective CDN architecture monitoring requires comprehensive visibility into all network components and nodes. PRTG sensors provide real-time monitoring capabilities essential for CDN performance optimization, tracking metrics across the distributed network:
- Cloud HTTP sensors monitor CDN endpoint availability and response times from multiple geographical locations
- Cloud Ping sensors measure latency and packet loss between PoP locations for connectivity assessment
- SNMP monitoring sensors track bandwidth utilization and web server performance metrics across CDN infrastructure
- Custom sensors monitor specific CDN metrics like cache hit ratios, origin server load, and API response times
These monitoring capabilities ensure your CDN architecture maintains optimal performance, handles traffic spikes effectively, and quickly identifies potential bottlenecks before they impact end users' experience or cause downtime.
CDN Architecture Traffic Routing: DNS vs. Anycast Methods
So now we've discussed the PoP physical layout and logical design with ECMP and BGP, but how do we direct user requests to the correct PoP? After all, this is the purpose of the PoP. We have two primary methods:
- DNS-based load balancing.
- Anycast routing.
DNS-Based CDN Architecture Routing
Traditionally, CDN designs started with each PoP advertising a different IP address to the WAN, informing end users of its location. This is combined with geolocation DNS-based load balancing through Domain Name System servers, to send user requests to one of those data centers. Each data center is configured with a different IP address for optimal routing.
DISADVANTAGES
The DNS-based load balancing method has plenty of shortcomings affecting CDN performance. The DNS server responds to the client based on the IP address of the resolver, not the actual client IP address, impacting content distribution efficiency.
An end user based in Europe could be configured to use a resolver in the USA. As a result, the data center IP address returned to the client will be based in the USA and not Europe. This is suboptimal in the sense that you can only run performance metrics to the DNS resolver IP and not to the client's IP address, affecting load times and user experience.
DNS-based CDN architecture also faces challenges with slower failover times and performance degradation from low DNS TTL (Time To Live) values. BGP routing provides quicker failover and high availability.
ADVANTAGES
The main advantage of DNS-based selection is full control over end user placement. Users are explicitly directed to specific data centers, providing direct control over capacity management. If a data center experiences traffic spikes, you simply redirect users elsewhere, preventing performance degradation.
Anycast CDN Architecture Implementation
Instead of using DNS to select the best PoP, Anycast routing uses the natural flow of the Internet for PoP selection and content distribution. Traditionally, with the DNS-based approach, PoPs are assigned a different IP address, but with Anycast each PoP is assigned the same IP address. Anycast routing is nothing new -- the entire global Domain Name System infrastructure is built using it.
The single IP address is advertised from multiple PoP locations and end users follow the natural flow of the Internet for PoP selection, which is based on hop count. DNS is still used, but instead of advertising many IP addresses, DNS advertises only one IP address. The Anycast routing approach does not use the resolver IP, but rather uses the client IP for routing decisions. This provides a better picture as to where users are located, enabling performance metrics and optimization to be run to the user's IP, not the resolver IP, improving overall CDN work efficiency.
Regional Anycast is often deployed with multiple regions participating under one address, typically 4 or 5 Anycast regions with different IP addresses for better scalability.
DDoS PROTECTION BENEFITS
Anycast routing provides excellent DDoS protection and mitigation against distributed denial of service attacks. IoT-fueled botnets generate Terabyte-scale DDoS attacks that overwhelm traditional centralized systems.
Anycast routing naturally absorbs distributed DDoS attacks, with every PoP and edge server sharing the load across the network of servers. As DDoS attacks increase in size, distributed network architecture is essential for maintaining CDN functionality and robust security features.
DISADVANTAGES
Anycast routing requires some stickiness for web applications, and directs end users based on fewest hops through the network topology, but this doesn't necessarily mean lowest latency or fastest response times. A single hop may have higher latency than multiple shorter hops, significantly affecting page load times and user experience.
However, strategically placed CDN PoPs in various geographical locations typically avoid high latency intercontinental connections, reducing physical distance and improving content delivery.
ADVANTAGES
Anycast routing does not suffer from any DNS correlation issues and can use high DNS TTL values. This enables the resolver to cache the response for future requests, providing better overall user experience and reduced load times.
CDN Architecture Security & Monitoring
Modern CDN architecture implements multiple security features including Web Application Firewalls (WAF) at edge server locations, SSL/TLS termination at PoP level, and rate limiting mechanisms to handle traffic spikes.
PRTG sensors monitor security-related CDN metrics in real-time: SSL certificate expiration across PoPs, suspicious traffic patterns and DDoS attack indicators, geographic traffic distribution anomalies, and response time degradation indicating potential attacks.
CDN Architecture Best Practices
Enterprise CDN architecture implementation should consider:
- Multi-CDN Strategy: Multiple CDN providers for redundancy and high availability
- Real-time Monitoring: Comprehensive network monitoring solutions like PRTG to track CDN performance
- Geographic Optimization: Strategic PoP placement based on end user demographics
- Cache Optimization: Intelligent caching policies for static content, dynamic content, and API responses
This article is part of a series: Part 1: Accelerate Your Apps With a CDN | Part 3: CDN Performance Metrics
Monitor Your CDN Architecture with PRTG Sensors
PRTG offers specialized sensors for comprehensive CDN architecture monitoring:
- Cloud HTTP Sensor: Monitor HTTP/HTTPS availability and performance from global geographical locations
- Cloud Ping v2 Sensor: Test connectivity and latency to CDN endpoints worldwide for optimal response times
- HTTP sensors: Track origin server performance, cache hit ratios, and offloading efficiency,like the HTTP v2 sensor.
- SSL sensors: Monitor SSL certificate status across all PoP locations and edge servers
- Custom sensors: Create tailored monitoring for specific CDN metrics, bandwidth utilization, and content purge operations

These PRTG sensors provide the visibility needed to maintain optimal CDN architecture performance, monitor cached content delivery, and quickly identify issues before they impact end users or cause website performance degradation.
Ready to optimize your CDN architecture monitoring and improve user experience? Try PRTG's comprehensive CDN monitoring sensors with a free 30-day trial - no credit card required.
Start your Free PRTG Trial and monitor your CDN architecture with specialized sensors for Cloud HTTP, Cloud Ping, and custom CDN metrics.











