 Published by Greg Campion
Published by Greg Campion
Last updated on January 23, 2024
•
7 minute read
In part 1 of our look at the future of infrastructure, I covered how the cloud, containers, and serverless are all shaping IT. I also briefly explained how important observability is becoming. In this post, I'll go into more detail about exactly what it is, and why it is so important. You can also check out an in-depth interview with me about this topic here:

An Example of Observability
To try and make this more tangible, let’s try a thought experiment, where we follow a hypothetical investigation of a problem:
You get an alert that an abnormal number of customers are leaving your site before checking out and buying your widgets. To get such an alert, you need to be logging and monitoring customers’ journeys through your site to determine a rate of success/checkout. This in turn means your applications need to be tracing and logging this information.
To figure out why an abnormal number of customers are leaving without purchasing, you take a look at your tracing and see that right after the user clicks to add something to their cart, there are timeouts occurring. You’ve built in retries so that even when there are timeouts, the item is still added. Despite this, the user experience is less than optimal, since this lag means that sometimes, when they go to checkout, nothing is in their basket. This level of tracing means that you are storing data for a large sample of the executions of your application’s logic so that you can see these retries and associate it with the requests from the customers, as well as with the customers themselves.
Once you determine which part of your application is causing issues, you then look at the outputs of that logic. Let's say you determine that sometimes, when your function is writing to the database, it takes too long, and the function times out. To get this kind of information, your application needs to be outputting detailed data each and every time it’s run.
You notice, however, that this timeout is only happening with specific instances of your function, and upon inspection you find that they are running the new version of the code that was released earlier that day in a blue-green setup. The instances that are running that new code are are the ones that are timing out. To determine this, an output of your function would have to be which version of your code it’s running.
When you look at the new code for that specific function, you notice that the developer decided to use a new library to interact with the database, and it’s decidedly slower than the previous one which is causing the writes to be too slow. You've found the reason for the timeouts, and therefore also for why customers are leaving without purchasing.
You can then roll back that deployment, fix the code and roll it out again with only a small percentage of your customers having had an issue.
This kind of analysis is only possible when you are running an observable system. If you had only been monitoring the stats on your DBs and the hosts running the application, the above problem would not have been caught. Perhaps, if you had seen similar situations like this before, you could have been monitoring for this specific situation. But the whole point of observability is monitoring for the unknown unknowns in your environment.
Unknown Unknowns
If you truly want to be able to truly observe a system, you need the kind of raw, highly cardinal data that is described in the example above, otherwise you cannot ask different questions than the ones you’ve already asked.
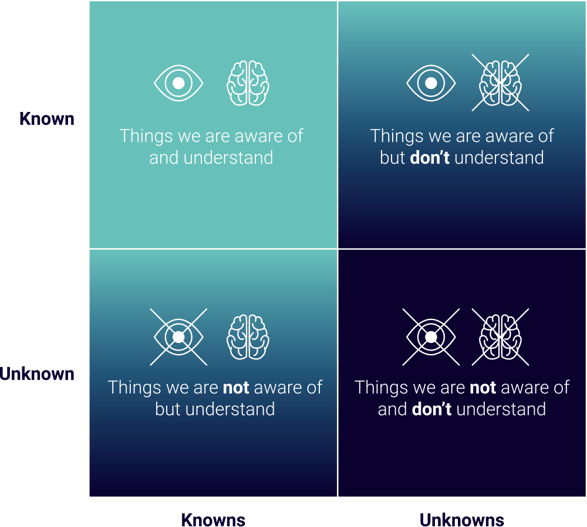
When you initially set up traditional monitoring, you set it up to monitor your known knowns, or in other words, what you think or know will fail.
While running your infrastructure, things will fail that weren't monitored, and so you start monitoring these—your unknown knowns.
To catch the known unknowns, you try to monitor your overarching infrastructure in order to be aware of them and then to understand them.
What can really ruin your business are the unknown unknowns. These are the things we aren't aware of, don't understand, and don't monitor. This is where observability really comes into play.
Currently almost everyone is monitoring for past or expected failures.
We build dashboards and sensors and consume metrics based on previous experiences. The human brain is trained to expect that what happened in the past is what will happen in the future, and monitoring for these things is needed. But to be able to see and react to the unknown unknown events that can and will happen, we have to make our systems more observable.
Almost everyone in IT is dealing with more and more complex and distributed systems, and if we want to make sure that our users are having a good experience, we have to simulate and track that experience. The first step in the thought experiment above is only possible when you simulate, test and evaluate your systems from the outside.
This is all well and good and should be done for any critical systems, but once you’ve seen that there is an issue, you then have to be able to slog through the data from the systems inside the black box and be able to cut and shift your data in ways that can help you find new answers to questions that haven’t been asked before.
Observability as a Buzzword
For a lot of people, what I am talking about here is something they already do, and they will say that observability is just a buzzword for what everyone should already be doing. I would offer a counter argument to that. If a new word for an existing idea comes about, it can be helpful in that it gives spark to the debates and new thinking like the ones we are now seeing in monitoring thanks to the word "observability".
Having been responsible for monitoring as a Systems Administrator as well as having worked on a DevOps team now for a few years as a software engineer, I think it’s time to bridge the monitoring gap and start making systems more observable so that alerting is more effective and troubleshooting is easier. This will allow operations and developers to work together more effectively and harmoniously.
Modern systems and the adoption of the cloud require that we reconsider how we monitor the systems we run, and I think observability and the discussion around it is helping shape those considerations. The cloud, serverless and containers are allowing us to develop faster and create better applications for others, and I’m personally glad to not have to drive down to the data center each time a server bites the dust and have relegated my ear plugs to the waste bin :)
Join the Discussion!
What do you think about my thoughts in this post (and the previous one)? Do you agree, or do you think I'm way off track? This is a discussion I would love to have, so make sure you put your opinion in the comments below! Just be nice about it :)











