Published by Shaun Behrens
Published by Shaun Behrens
Last updated on May 13, 2026
•
14 minute read
When my son broke his arm, IT infrastructure was genuinely the last thing on my mind. Obviously. But there I was, in an emergency room, watching a radiographer try and fail to get an X-ray machine working. She kept clicking, rebooting, apologizing. Twenty minutes passed. Eventually she told us the machine wasn't communicating with the hospital's systems. My son got his X-ray in the end, clean fracture, nothing dramatic, but I couldn't let it go on the drive home.
Because in a setting where time actually matters, how much of modern healthcare depends on IT just... working? Turns out: almost everything.

The Cost of Downtime in Healthcare IT
Think about what a hospital runs on today. Electronic patient records. Diagnostic imaging moving across networks. Medical devices feeding data into central systems. Every clinical workflow, from scheduling to lab results to discharge paperwork, depends on software integrations that someone has to keep running around the clock. That's real progress. But it comes with a catch.
When IT fails in healthcare, the consequences aren't abstract. Hospital IT outages have been linked to delayed diagnoses, cancelled procedures, and in the worst cases, patient outcomes that nobody wants to put in a report. And that's before you get to the financial side: revenue loss from disrupted services, SLA penalties, and the kind of damage to customer trust that a press release doesn't fix.
IT teams in healthcare carry a lot. They're managing complex, heterogeneous infrastructure with lean teams and budgets that rarely match the scope of what they're responsible for. And the gap between "something is degrading" and "a clinician can't do their job" is shorter here than in almost any other industry. That's not an exaggeration.
Which is why uninterrupted service monitoring isn't just a nice-to-have. It's a practical necessity.
Anatomy of the Modern Medical IT Infrastructure
Before you can monitor something properly, you need to understand what you're actually dealing with. And healthcare IT is genuinely complex, more so than a typical enterprise network, and getting more complex every year.
At the core of most hospital environments, you'll find several interconnected systems:
- PACS (Picture Archiving and Communication System): stores and distributes medical imaging data like X-rays, MRIs, and CT scans
- RIS (Radiology Information System): manages radiology workflows and patient scheduling
- HIS (Hospital Information System): the central hub for patient administration, billing, and clinical records
- LIS (Laboratory Information System): handles lab orders, results, and reporting
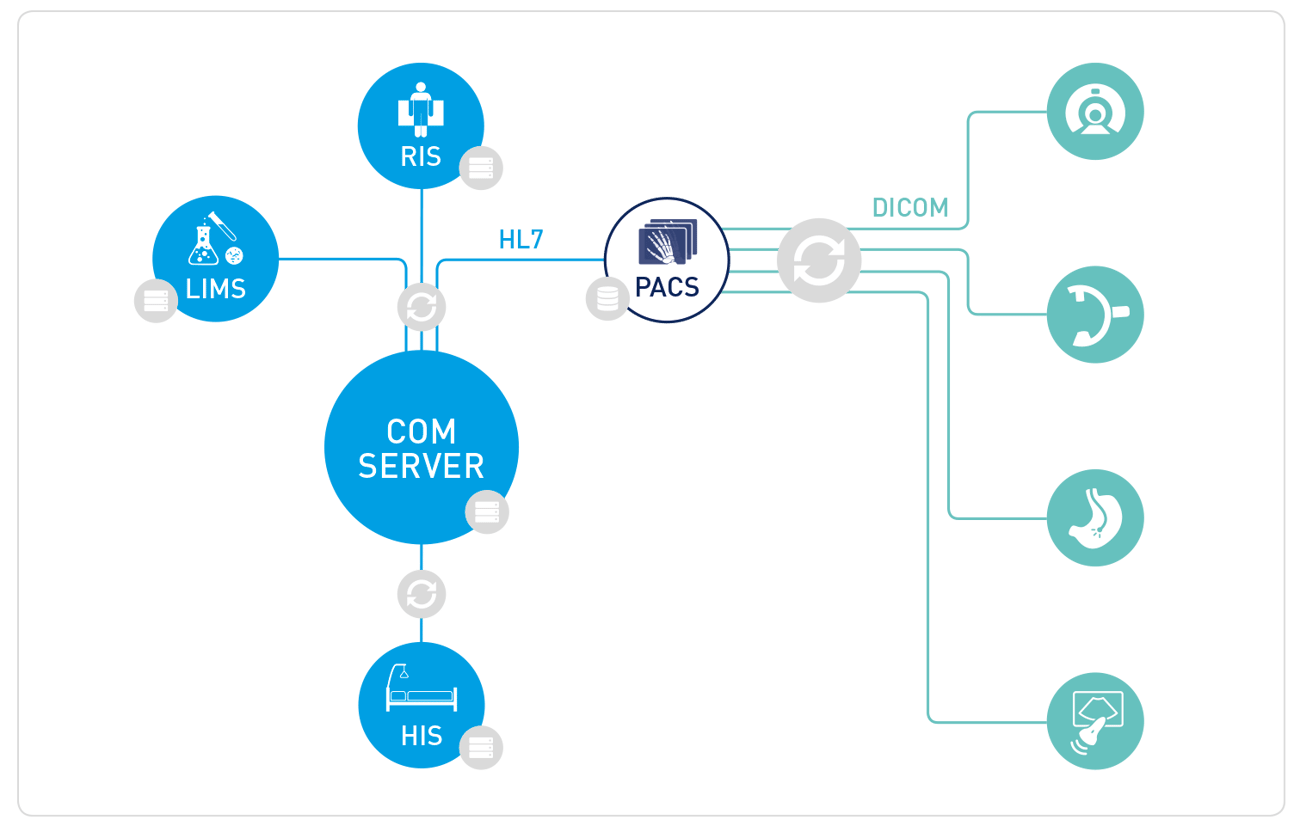
- Integration Engine: the middleware layer that lets all of these systems talk to each other and to external service providers
Connecting all of that are the usual network components: servers, switches, routers, firewalls. And layered on top is a rapidly growing ecosystem of IoT medical devices. Patient monitors, infusion pumps, imaging machines, diagnostic equipment, all connected, all dependent on the network to function as intended.
Every one of those layers is a potential failure point. The integration engine alone can process hundreds of thousands of transactions a day. When it stalls, the effects ripple outward fast. It's a lot to keep track of, and most healthcare IT teams need a structured approach just to know where to start.
So What Should be Monitored?
Let me break this into four areas. These are the ones that actually move the needle.
1. Digital Medical Devices
Medical devices are network endpoints now. That's just the reality. Imaging machines, patient monitors, diagnostic equipment, all connected, all capable of failing in ways that disrupt care delivery. Sometimes quietly, sometimes not.
Most of these network devices communicate via SNMP (Simple Network Management Protocol), which tells you whether something is reachable. Useful, but limited. For richer data like application-level health, device-specific error states, and usage metrics, you typically need RESTful APIs, where the device or its management system exposes more detailed information that a monitoring system can pull and track over time.
At minimum, you want to know: is the device available? How fast is it responding? Are there active error states? Is it talking to the systems it's supposed to feed? That's your baseline.
2. The Integration Engine
If the medical IT environment has a central nervous system, this is it. Systems like Mirth Connect or Rhapsody sit between PACS, HIS, LIS, RIS, and everything else, translating messages and routing data. When the integration engine slows down or fails, the downstream effects are immediate and broad.
Monitoring it means watching message throughput, queue depths, error rates, and response times. A growing queue backlog or a spike in failed messages is usually an early sign that something upstream is struggling. Catching that before it shows up in a clinical workflow is the whole point of a proactive approach to monitoring.
3. Communication Between Medical Systems
Healthcare systems rely on two dominant communication protocols: DICOM (Digital Imaging and Communications in Medicine) and HL7 (Health Level Seven). These are the languages that medical systems use to exchange imaging data and clinical information.
Monitoring the health of these protocol-level connections, including latency, throughput, and error rates, gives IT teams early visibility into communication failures. A DICOM interface that's responding slowly, or an HL7 feed that's dropping messages, will show up in your monitoring data well before a radiologist notices something is missing from their worklist. That lead time matters.
4. Traditional IT Infrastructure
Underneath every healthcare application is a layer of traditional IT infrastructure: servers, network switches, routers, firewalls, and the physical or virtual fabric that ties everything together. These are the foundations. And they need the same rigorous monitoring as the clinical systems sitting on top of them.
The metrics that matter break down like this:
| What to watch | Why it matters |
| CPU and memory utilization | Application performance on clinical servers directly affects workflow speed |
| Network traffic and bandwidth | Traffic patterns reveal bottlenecks before they start affecting throughput |
| Latency across segments | High latency between PACS servers and workstations shows up as delays at the point of care |
| Firewall health | Legacy medical device software carries known vulnerabilities; security threats targeting healthcare are frequent and getting more sophisticated |
Bottlenecks at this layer build gradually. By the time a clinician notices performance has degraded, the disruption is already happening. Infrastructure problems rarely announce themselves loudly. They creep.
From Reactive Firefighting to Proactive Monitoring
Here's the shift that actually changes things. Moving from reacting to problems after they surface, to catching them before they do.
Continuous performance monitoring means setting thresholds on the metrics that matter, CPU load, bandwidth utilization, message queue depths, device response times, and getting automated notifications when those thresholds are breached. Your team gets an alert the moment message throughput drops below normal. Maybe that's 30 minutes before the problem becomes visible in a clinical workflow. Maybe it's two hours. Either way, you're ahead of it instead of behind it.

Visibility without context is just noise, though. When you can see the current state of your entire infrastructure, medical devices, integration engine, protocol-level communication, traditional IT, all in a single dashboard, you can prioritize responses and make informed decisions under pressure. Historical data adds another layer: trend analysis becomes possible, recurring network performance issues can be spotted before they repeat, and you build a record that actually supports investment decisions when budget conversations come around.
And there's a less obvious benefit that doesn't get talked about enough. Teams that aren't constantly firefighting have time to actually improve things. In healthcare IT, that's not a small thing.
Performance Metrics That Actually Matter
In a healthcare IT environment, a handful of performance indicators connect infrastructure health directly to clinical outcomes. These are the ones worth tracking consistently, not because a checklist says so, but because they're the ones that show up when things go wrong.
| Metric | What to look for |
| Uptime and availablity | For critical systems like PACS and HIS, anything below 99.9% needs explanation and a remediation plan |
| Response time | Slow responses in radiology workflows or EHR access degrade the user experience for clinical staff. The friction builds quietly, not dramatically |
| Latency | Large DICOM files need to move fast. High latency between PACS servers and workstations shows up directly as delays at the point of care |
| Error rates and failed transactions | Especially on the integration engine. A rising error rate rarely stays stable on its own, and it's usually the earliest signal that something is wrong |
| SLA compliance | Healthcare organizations operate under service level agreements with internal stakeholders and external providers. Continuous monitoring of this performance data is the only reliable way to catch violations before they become contractual problems |
Taken together, this is what observability actually means in practice. Not just knowing that something failed, but having the data to understand why, and the history to spot it coming next time.
Why PRTG Works Well for Healthcare IT
At some point, the conversation has to get practical. A monitoring strategy is only as good as the tool running it, and healthcare IT has specific requirements that generic network monitoring solutions don't always meet.
PRTG Network Monitor by Paessler is used by IT teams in hospitals and healthcare organizations across a wide range of environments, from single-site hospitals to multi-campus networks. What makes it relevant here is that it covers the full stack described in this article: medical devices via SNMP and REST API, integration engine health, DICOM and HL7 protocol monitoring, and traditional IT infrastructure, all in one place. You're not stitching together separate network monitoring tools for different layers and hoping the picture adds up.
A few specifics worth knowing:
- SNMP and REST API monitoring for medical devices and integration engines
- Custom sensors for DICOM and HL7 protocol health
- Real-time dashboards configurable for different teams: clinical IT, network ops, management
- Threshold-based alerting with notification channels including email, SMS, push, and ITSM integrations
- Historical data and reporting for trend analysis, capacity planning, and SLA documentation
- Sensor-based architecture, so teams can start focused and expand coverage as needed
PRTG functions as a unified monitoring service across both traditional IT and healthcare-specific systems. That matters because the visibility gaps in most healthcare environments don't come from a lack of tools. They come from too many tools that don't talk to each other. That's a different problem, and it needs a different solution.
Uninterrupted Service Starts With Visibility
My son got his X-ray. Clean fracture, nothing serious. But that 20-minute wait, because an imaging machine couldn't communicate with the hospital's systems, stayed with me longer than the hospital visit itself.
In that situation, the stakes were low. In a lot of situations in a hospital, they're not.
Healthcare IT teams know this better than anyone. Infrastructure failures here don't just mean SLA breaches and revenue loss. They touch patient care. And the people walking through the door of a hospital aren't thinking about network uptime or system performance or integration engine throughput. They're just expecting the technology to work.
Getting visibility into the full environment, catching potential issues before they surface clinically, and having the performance data to act fast when something does go wrong, that's what uninterrupted service monitoring actually delivers. It's less about the technology and more about what it makes possible.
See what PRTG can do for your healthcare IT environment - before the next outage forces your hand.