In this series of blog articles I will share with you six steps that will help make your business failure tolerant. — See also: The Complete Series
If your business relies heavily on the availability of your website and online shop, the second step right after choosing the right hosting provider is to make sure your hosting is failure tolerant so that it stays online even if components fail.
Providing redundancies is essential. If technically possible we always try to set up "auto-healing" mechanisms which kick in immediately whenever a failure happens.
Let's look at the details or our website setup.
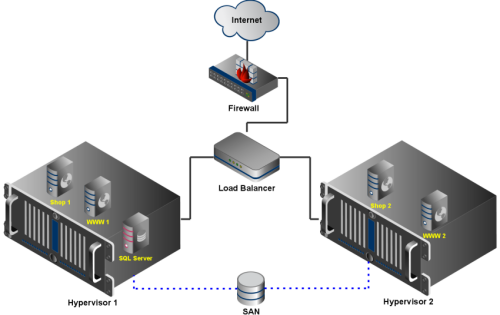
For our website we have been running a virtual private cloud at Rackspace since 2009 (blog post www.paessler.com Runs on New Hardware and Software). We have two hypervisors connected to the Rackspace SAN and they run five virtual machines (two Linux web servers for paessler.com, and two Windows web servers for our shop/CRM system, as well as one Linux database server). Each of the two hypervisors is able to run the whole set of virtual machines alone at any time. If one hypervisor crashes, VMware High Availability (HA) automatically starts the virtual machines on the other server. Auto-healing!
Also the two Linux web servers and the two shop servers are two redundant pairs. We have a hardware load balancer in front of the web servers that distributes the requests to our website on to both servers. If one server fails (or has to be rebooted) the load balancer automatically moves all traffic to the remaining web server. Auto-healing! Using virtual machines of course allows us to use all the other cool VMware features like snapshots and moving virtual machine images to our office etc. We can even upgrade the hypervisors to other server hardware without downtime!
In the unlikely case we lose the whole Rackspace datacenter we have a "Plan C": We always have a 1:1 replica of the Dallas setup in the datacenter of IPExchange just outside our hometown of Nuremberg, Germany. This setup is also used for testing and development of CMS and shop systems. The database is permanently replicated from Dallas to Nuremberg, too. It takes us just a few clicks and a simple change in the DNS entry for paessler.com to actually serve our website and shop from Nuremberg. Well, almost auto-healing.
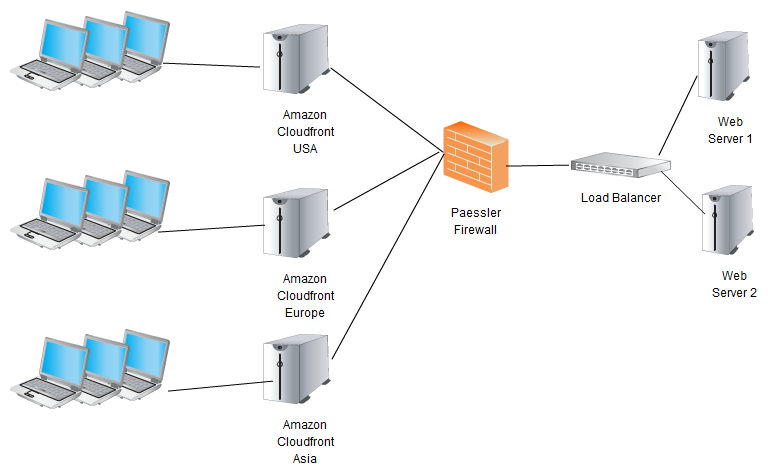
And earlier this year we added another layer of redundancy on top: We are actually serving the website paessler.com "through the CloudFront CDN" (blog post Hosting a Website Through Amazon CloudFront). I mean we not only serve images, JavaScript and CSS from the CDN, as most companies do. We also serve the HTML through CloudFront.
When you surf on paessler.com your browser actually doesn't even talk to our web servers, it only talks to the nearest edge servers of the Amazon content delivery network which most of the time have a copy of our website in their memory (or they go get it for you). This means the website is really fast (no transatlantic/transpacific latency in Europe/Africa/Asia) and a short downtime of our website would not be noticeable, too.
Of course this can only be done with static or almost static content; it is not suitable for forums and other web pages with interaction. If we make a change to our website's content and want this content to be online immediately we must purge the corresponding URL from the CDN using an API call to Amazon (this is a feature of our homegrown CMS).
All of the concepts mentioned above that we use with our virtual private cloud can also be used with one of the public clouds. Yes, it may be cheaper, but we would not "go cloud" for our website. In a cloud environment one would have to implement even more redundancy. In such an environment you must even more "design for failure" (see The AWS Outage: The Cloud's Shining Moment).
In the next blog post, I will talk about how to provide redundancies in your office IT infrastructure, too.
At Paessler we have been selling software online for 15 years and we have had hardware, software, and network failures just as everybody else. We tried to learn from each one of them and we tried to change our setup so that each failure would never happen again.
Read the other posts of this series:
{kind=link}
{kind=link}